最近沉迷于 Vibe Coding,开发文章编辑功能,于是觉得有必要梳理一篇网页编辑器考古文。
富文本编辑器的发展史,本质上是一场关于控制权的争夺。浏览器厂商、框架作者、产品经理、终端用户,乃至今天的 AI 模型,都在争夺同一个问题的答案:谁来决定一段文本的最终形态?这场博弈从 1990 年代的 contenteditable 开始,历经 HTML 封装、Canvas 自绘、Markdown 极简主义、JSON 结构化模型,直到今天 AI 时代 Markdown 的意外回潮。每一次技术范式的切换,都不是简单的替代,而是编辑权与渲染权分离程度的重新校准。

第一章:混沌初开——浏览器原生的 contenteditable 时代
最早的 Web 编辑器没有框架,只有浏览器提供的 contenteditable 属性。将任意 HTML 元素标记为可编辑,浏览器便会接管光标、选区和输入事件,开发者只需在之上叠加工具栏。然而,这种“免费”的便利背后是不可控的黑暗森林。
2014 年,Medium 工程师 Nick Santos 发表了那篇著名的《Why ContentEditable is Terrible》,用近乎数学公理化的方式证明了原生 contenteditable 的三大缺陷:DOM 内容与可见内容之间的映射是“多对一”的混乱关系;DOM 选区与可见选区之间更是“多对多”的灾难;跨浏览器编辑操作无法形成代数封闭的完备集合 。这意味着,同样的加粗操作在 Chrome、Firefox 和 Safari 中可能产生完全不同的 HTML 结构,粘贴外部内容时更是会引入无法预测的样式标签contenteditable 试图成为一个通用的 WYSIWYG HTML 编辑器,但正如 Santos 所言,这与“良好的所见即所得体验”在根本上是互斥的。
第二章:HTML 至上——WYSIWYG 的封装时代
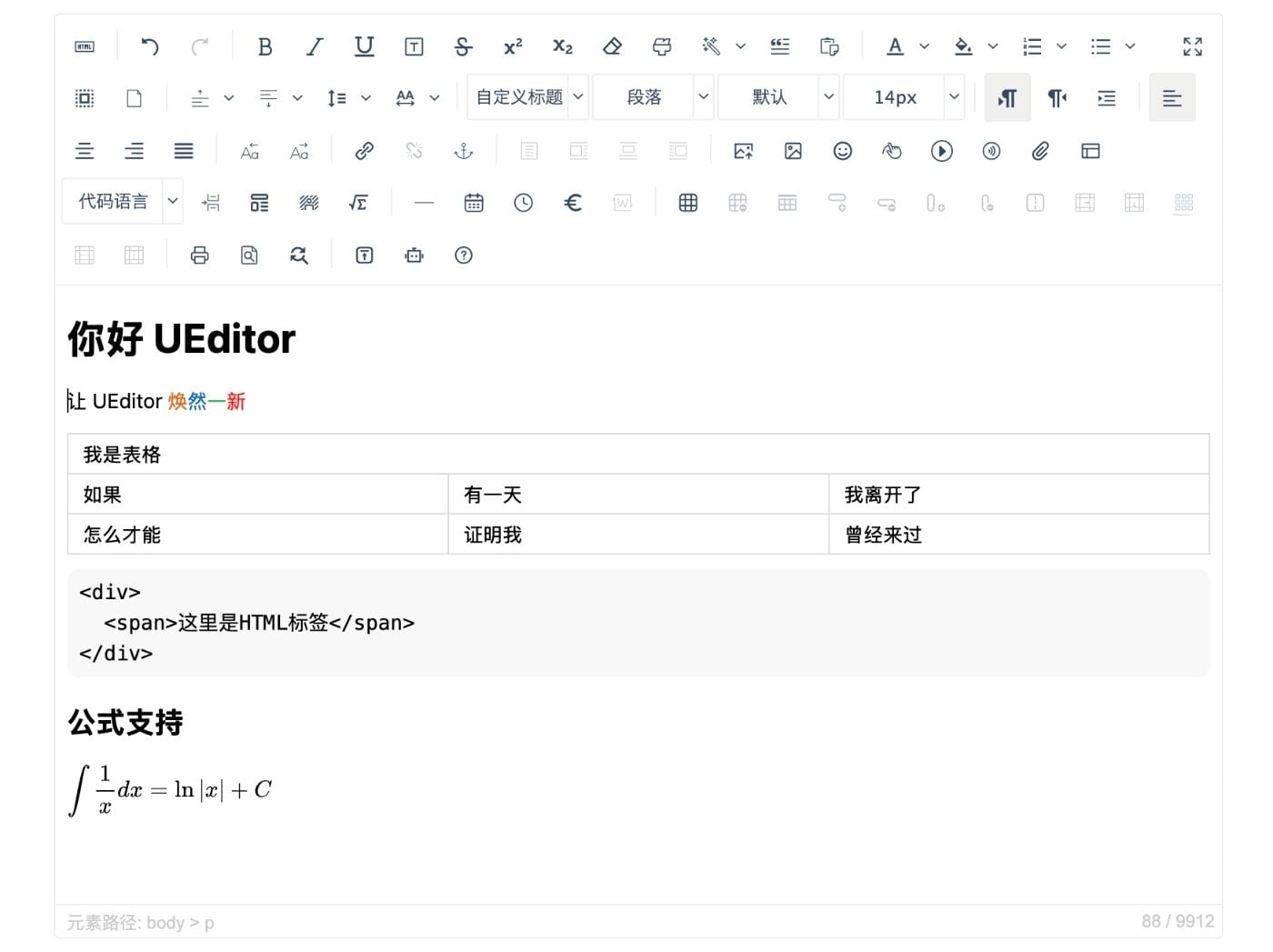
既然浏览器原生实现不可靠,开发者便开始在 contenteditable 之上构建封装层。CKEditor、TinyMCE、UEditor 等经典编辑器通过拦截 document.execCommand,用自己的命令系统替代浏览器默认行为,试图在混乱之上建立秩序。这一阶段的核心特征是:HTML 既是编辑器的内部状态,也是最终渲染结果。
然而,这种架构存在一个结构性矛盾:编辑器为了控制表现,不得不维护一套私有样式和 HTML 规范,但它又无法完全抛弃浏览器的渲染管线。HTML 与最终视觉呈现之间仍然隔着 CSS 解析、浏览器默认样式和平台差异的漫长路径。WYSIWYG(所见即所得)在此变成了一种近似幻觉——用户在编辑器中看到的,与邮件客户端、移动端或打印预览中看到的,往往并非同一回事。
第三章:逃离 DOM——Canvas 自绘与视图模型的分离
对 HTML 路径的失望,催生了一场更为激进的叛逃。Google Docs 的新版编辑器彻底放弃了 contenteditable 和 DOM,转而基于 Canvas 自绘整个编辑界面:自己管理光标、自己实现文本布局、甚至自己解析字体 。腾讯文档、WPS Web 版也走上了类似的道路,无论是否使用 Canvas,核心思路都是独立实现编辑与排版功能,将浏览器降级为一块像素画布。
这种 L2 级编辑器的优势显而易见:跨平台一致性、精确的像素级控制、协作编辑的自然支持。但它的代价同样高昂——如此重度的工程投入,只能由巨头维持,核心技术几乎不可能开源。这标志着编辑器架构的第一次根本性分离:文档模型与渲染视图彻底解耦。编辑操作不再直接修改 HTML,而是修改一个抽象的数据结构,再由自绘引擎将其映射为像素。

第四章:极简主义——Markdown 的崛起与标记语言的边界
当 Canvas 自绘走向封闭的重工程时,另一条路径选择了截然相反的方向:极度简化。Markdown 的流行并非因为它强大,而是因为它有意识地放弃能力以换取一致性。CommonMark 和后来的 GitHub Flavored Markdown (GFM) 定义了一个最小可用的语法子集,使得后端渲染变得 trivial,任何文本编辑器都能成为 Markdown 的 WYSIWYG 前端。
然而,这种极简很快遇到了边界。插入媒体、复杂排版、交互组件——这些需求超出了 Markdown 的设计初衷。社区开始扩展语法,但方言的碎片化又削弱了“通用格式”的核心价值。Asciidoc、reStructuredText、MediaWiki 等替代方案在特定领域(技术文档、百科)取得成功,但没有一个能覆盖全部场景。Markdown 证明了轻量标记语言的价值,也暴露了它们的 ceiling。

第五章:扩展的困境——从 Remark 到 MDX
面对 Markdown 的表达能力瓶颈,社区探索出两条路径:降级回 HTML,或扩展标记语法。Hexo 的标签插件,都是在不破坏 Markdown 纯文本观感的前提下注入元数据。而 MDX 则走得更激进:它将 JSX 组件直接嵌入 Markdown,让 Markdown 从“标记语言”进化为“内容编程语言”。
MDX 的演进本身就充满启示。根据 John Otander 的回忆,MDX 最初的设计思路是“Markdown in JSX”——在 React 组件中通过模板字符串嵌入 Markdown。但很快发现,内容应该是第一公民,而非 JSX 的附庸。于是范式翻转,最终确立为“JSX in Markdown”,并通过 Babel 插件和 Webpack loader 在编译期完成转换,避免了运行时依赖 。MDX 在技术文档和组件库文档场景中取得了巨大成功,但它本质上是开发者的内容格式,依赖完整的 JS 运行时才能渲染,这使其难以成为大众编辑器或跨系统交换的通用底层。
第六章:结构化革命——JSON 文档模型与 ProseMirror 的范式转移
2015 年,Marijn Haverbeke——此前因 CodeMirror 名满天下的编辑器领域权威——开启了 ProseMirror 的众筹项目 。ProseMirror 的划时代意义在于,它首次系统性地提出了 Schema + Transform + Plugin 的三位一体架构:编辑器的状态是一个可序列化的 JSON 文档树,而非 HTML;所有编辑操作都是对 JSON 数据结构的纯函数变换;视图层只是这一模型的投影。
几乎与此同时,2016 年 Ian Storm Taylor 开源了 Slate.js,其核心理念与 ProseMirror 遥相呼应:Slate 的核心是一个“无预设 Schema”的纯 JSON 嵌套树模型,文档、选区、命令都围绕这一数据结构运作 。Slate 的文档模型极其简洁—EditorBlockInlineTextMark 五类节点构成全部世界,而序列化后的 JSON 完全可预测、可人工阅读 。
这一阶段标志着编辑器范式的彻底转向:HTML 不再是真相来源,它只是 JSON 模型的一种可能的渲染输出。ProseMirror 和 Slate 证明,编辑器的状态应该是一个与渲染无关的纯数据结构,而 HTML、Markdown、PDF 都只是这一模型的不同序列化视图。
第七章:协作的倒逼——从 OT 到 CRDT
JSON 文档模型的流行,与实时协作技术的成熟是同一枚硬币的两面。早期的协作编辑依赖 OT(Operational Transformation),但在 HTML 树或字符串上实现正确的 OT 算法极其复杂,边界情况极易导致状态不一致。
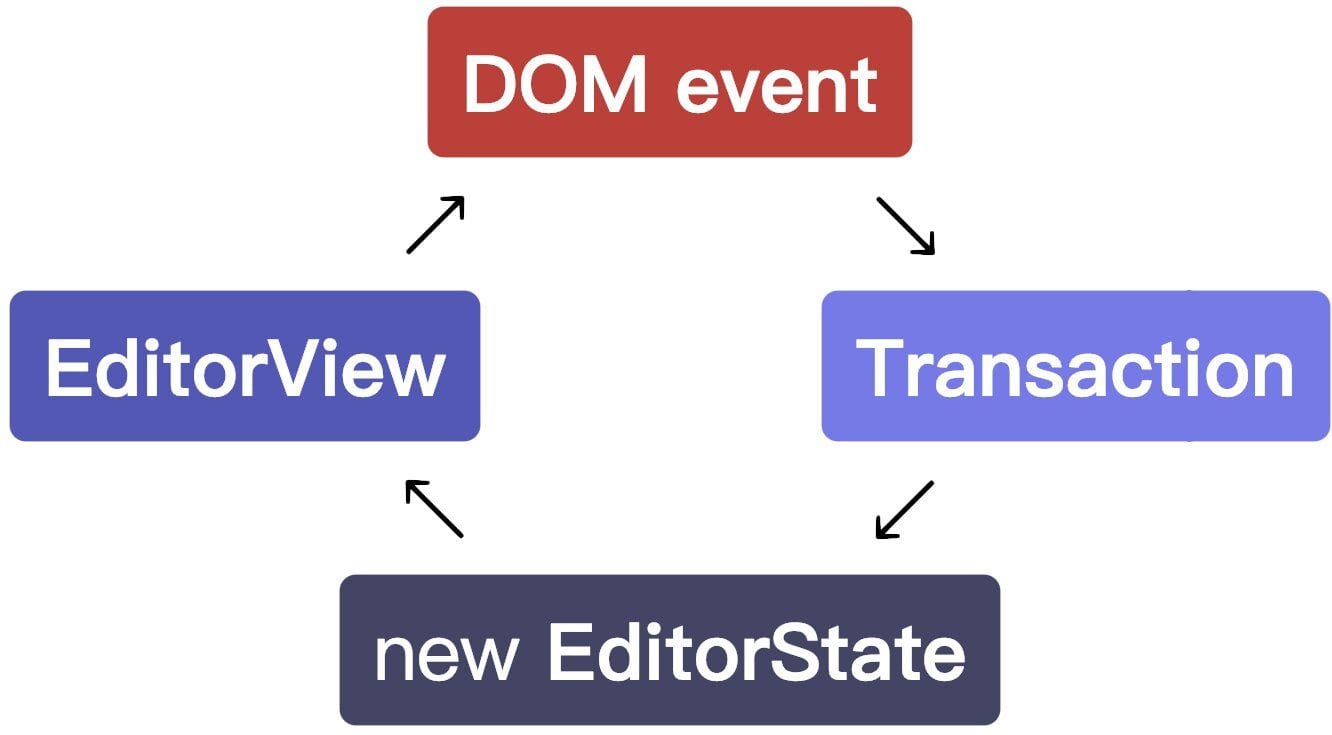
CRDT(Conflict-free Replicated Data Type)的崛起改变了这一局面。Yjs 作为当前最主流的 CRDT 库,采用 YATA 算法和二进制增量编码,能够高效处理文本编辑场景中的并发冲突 。更重要的是,Yjs 与 ProseMirror 的集成(通过 y-prosemirror 绑定)已经高度成熟:ProseMirror 的每一次 Transaction 被自动转换为 Yjs 的 CRDT 操作,网络层由 Hocuspocus 或 WebSocket provider 处理,开发者几乎无需关心冲突合并的细节 。
JSON/Block 模型之所以特别适合 CRDT,是因为树状结构天然支持按节点隔离冲突域。Notion 的块级模型(每个 Block 是一个独立节点)正是这一思路的极致体现——当两个用户同时编辑不同 Block 时,冲突解决是平凡的;即使在同一文本块内,Yjs 的 Y.Text 也能保证最终一致性。可以说,没有 JSON 文档模型的先声,现代 Web 协作编辑的民主化就不会发生。
第八章:Meta 的新赌注——Lexical 与 Block 编辑器的民主化
2022 年 4 月,Meta 开源了 Lexical,一个被定位为 Draft.js 继任者的可扩展文本编辑器框架 。Draft.js 曾基于 Immutable.js 为 Facebook 的笔记、评论和 Messenger 提供支持,但长期陷入维护模式,官方明确推荐用户迁移至 Lexical 。
Lexical 的设计哲学反映了 Meta 在超大规模场景下的经验:核心引擎仅 22kb(min+gzip),采用不可变状态树和事务批处理更新,与 React 的渲染模型深度对齐 。它通过插件系统按需加载功能——列表、链接、表格、Markdown 都是独立包,开发者只为自己使用的功能付费。在架构上,Lexical 同样遵循“模型优先”原则:它附着在 contentEditable 元素上,但开发者极少直接操作 DOM,而是通过声明式 API 与 Lexical 的编辑器状态交互 。
Lexical 的出现,加上基于 ProseMirror 的 Tiptap、BlockNote 等封装库的成熟,意味着结构化 Block 编辑器已经从 Notion 的闭源黑箱,变成了可复用的开源基础设施。这是 JSON 文档模型范式的最终胜利——它不再是先锋实验,而是行业标准。

第九章:AI 时代的回潮——Markdown 为何再次成为通用语
然而,就在 JSON Block 编辑器似乎要一统江湖之际,AI 大模型的爆发意外地将 Markdown 重新推上了王座。今天的 LLM 应用——从 ChatGPT 的 Canvas 到各类 RAG 系统——几乎无一例外地使用 Markdown 作为默认输出格式。
这种回潮有其结构性原因。首先,Markdown 的语法密度低,在 LLM 的上下文窗口中信息熵更高;其次,互联网的高质量训练语料(GitHub、StackOverflow、技术文档)本身就是 Markdown 为主,模型对其语法结构的先验知识更强;第三,Markdown 的双向可逆性——人类可以直接编辑模型生成的 Markdown,而无需理解复杂的 JSON 树结构。
但这也暴露了一个深刻的悖论:AI 需要 Markdown 的简洁,但用户需要 Block 编辑器的表达能力。当前的工程实践正在用“混合模型”弥合这一裂缝——底层存储和协作仍然基于 JSON/CRDT,但 AI 交互层使用 Markdown 作为“协议语言”,再由编辑器解析为 Block 结构。Notion AI、Obsidian 的 AI 插件,乃至各类 LLM 写作工具,都在采用这种双层架构。
结语:尚未终结的演进
从 contenteditable 的混沌,到 HTML 封装的挣扎,从 Canvas 自绘的封闭,到 Markdown 的极简,再到 JSON 模型的结构化和 AI 时代 Markdown 的意外回潮——这条曲线并非线性进步,而是一次次关于“谁掌握控制权”的螺旋上升。
Marijn Haverbeke 在 2015 年 salvage contentEditable 时,大概不会想到九年后 AI 会成为编辑器的核心用户之一;Meta 开源 Lexical 时,也未必预料到 Markdown 会在 LLM 语境下重新成为通用语。但贯穿始终的主线是清晰的:编辑器的状态必须是一个与渲染无关的、可序列化的、机器与人都能理解的数据结构。
谁能在 JSON 的结构性、Markdown 的文本友好性和 AI 的生成需求之间架起最优雅的桥梁,谁就能定义下一个十年的编辑器范式。这场演进,还远未终结。
{kind=link}
{kind=link}
内容很详细哈,排版也漂亮。虽然很少见到用富文本编辑器了。
我个人用的是Vditor,我还是比较喜欢用Markdown语法自己来排版
Markdown 语法对我来说,还是不够用,我现在已经完全放弃 Markdown,改用 JSON 格式了。
博主后台用的是什么文本编辑器啊,最近在做自己的博客,想参考一下。
目前的后台编辑器使用的和前端你在评论框使用的编辑器是同一种,就是 Taptap。
博客的源码是完全开源的,你可以直接抄过去。https://github.com/syhily/yufan.me
完了,看到md就习惯性的把它扔 Claude Code里面去了。
笑死,我看到什么想抄的项目,也是习惯性地丢 Claude Code。
难得见你写一篇技术文章。
怎么没提一嘴PortableText。BlockNote 太离谱了我觉得,连文档都是收费的,集成后我写了一篇测试文章后就把它废掉了。
ChatGPT桌面版现在是怎么回事,已经完全无法渲染公式了。
另外,昨天刚把我的表格编辑器改成了JSON,之前是存的HTML。api: getJSON · movsb/javascript-table-editor@943b5e7。
PortableText 在这里面其实就算是个小虾米,我个人认为没必要专门去提及它。它本身是 Sanity CMS 这个公司的一种格式约定而已,也算是一种方言。