
Background
In the application scenarios of Elasticsearch, the storage of large amounts of data may significantly impact the read and write performance of Elasticsearch. Therefore, it is necessary to split indexes according to certain data types. This article explains through relevant technical research whether splitting data on Elasticsearch will affect query results in AI search scenarios. It also compares the implementation principles of other vector databases currently available in the industry with those currently using Elasticsearch.
Goals
- Elasticsearch vs. Milvus: Comparison in AIC use cases
- Investigate the data storage mechanisms and query processes of mainstream vector databases in the current industry (Qdrant, Milvus). Conduct an in-depth analysis of how they handle data updates (such as incremental updates and deletion operations) and compare them with Elasticsearch.
- The impact of single-table and multi-table design on similarity calculation in the Elasticsearch BM25 model
- Study the Elasticsearch differences between single-index and multi-index structures in the BM25 calculation, particularly their impact on efficiency and accuracy during calculations.
Elasticsearch vs. Milvus: Comparison in storage, query, etc
Overall Architecture
Elasticsearch Architecture
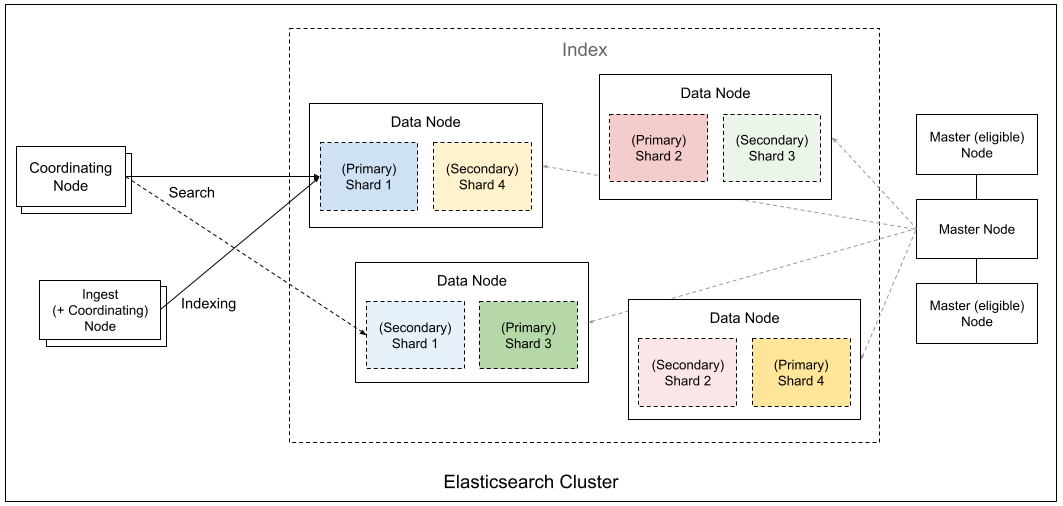
Elasticsearch architecture is straightforward. Each node in a cluster can handle requests and redirect them to the appropriate data nodes for searching. We use blue-green deployment for scaling up or down, which enhances stability requirements.
Cons: Currently, we only use two types of Elasticsearch nodes: data nodes and master nodes. Every data node serves all roles, which may not be as clear-cut as Milvus's architecture.
Multiple Milvus Architecture
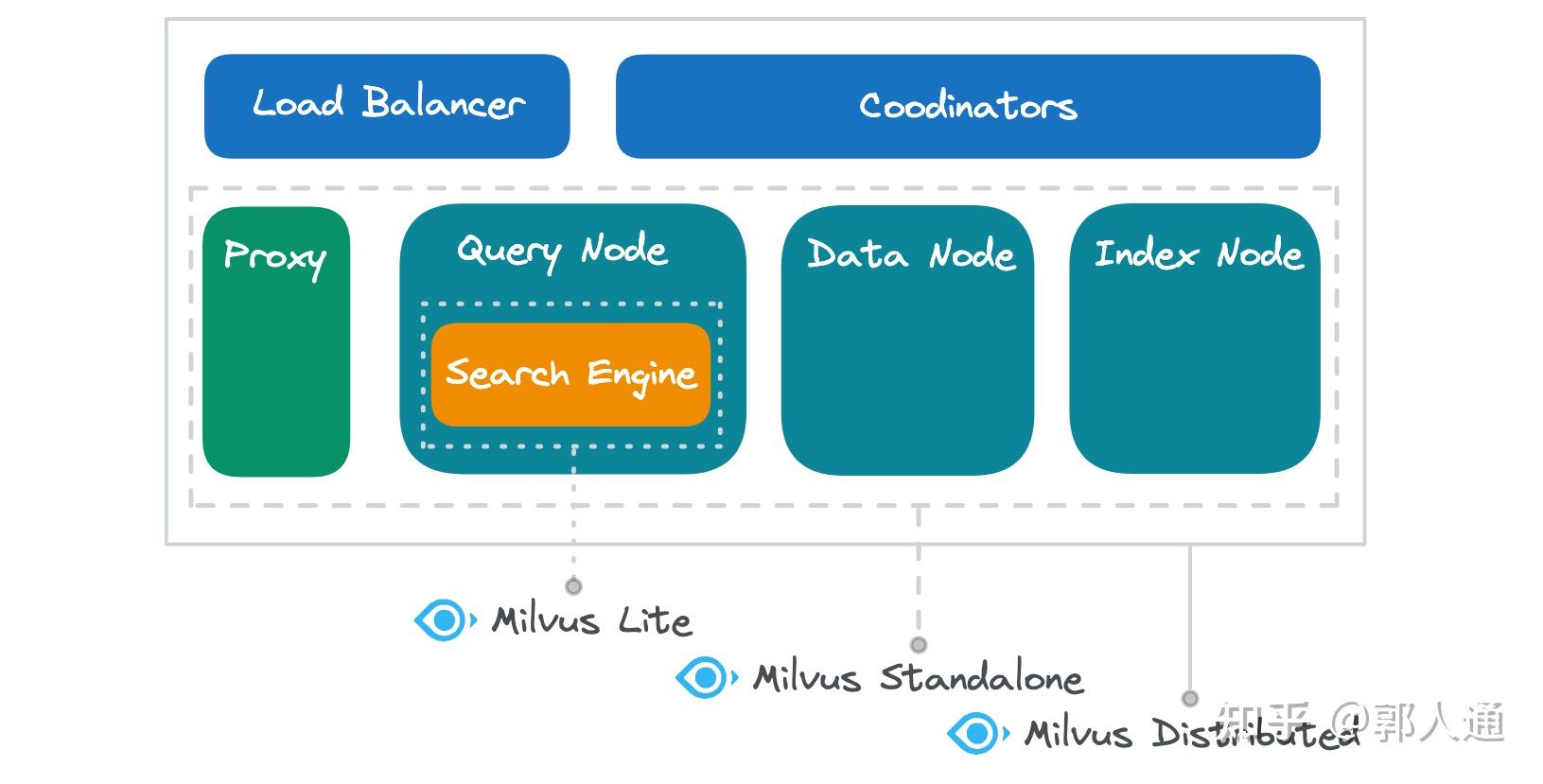
The Milvus Lite is the core search engine part with the embedded storage for local prototype verification. It's written in Python and can be integrated into any AI python project.
The Milvus standalone is based on Docker compose with a milvus instance, a MinIO instance and an etcd instance. The Milvus Distributed is used in Cloud and production with all the required modules. In the most case, we are talking about the Milvus Distributed in this report.
Milvus Distributed Architecture

Milvus has a shared storage massively parallel processing (MPP) architecture, with storage and computing resources independent of one another. The data and the control plane are disaggregated, and its architecture comprises four layers: access layer, coordinator services, worker nodes, and storage. Each layer is independent of the others for better disaster recovery and scalability.
- Access Layer: This layer serves as the endpoint for the users. Composed of stateless proxies, the access layer validates client requests before returning the final results to the client. The proxy uses load-balancing components like Nginx and NodePort to provide a unified service address.
- Coordinator Service: This layer serves as the system’s brain, assigning tasks to worker nodes. The coordinator service layer performs critical operations, including data management, load balancing, data declaration, cluster topology management, and timestamp generation.
- Worker Nodes: The worker nodes follow the instructions from the coordinator service layer and execute data manipulation language (DML) commands. Due to the separation of computing and storage, these nodes are stateless in nature. When deployed on Kubernetes, the worker nodes facilitate disaster recovery and system scale-out.
- Storage: Responsible for data persistence, the storage layer consists of meta storage, log broker, and object storage. Meta storage stores snapshots of metadata, such as message consumption checkpoints and node status. On the other hand, object storage stores snapshots of index files, logs, and intermediate query results. The log broker functions as a pub-sub system supporting data playback and recovery.
Even in a minimal standalone Milvus deployment. We need an OSS service like Minio or S3, A etcd standalone cluster and a milvus instance. It's quite complex architecture and mainly deployed and used on K8S.
Summary
| Elasticsearch | Milvus | |
|---|---|---|
| Complexity | Simple, only master nodes and data nodes. | Complex, require OSS, etcd and different types of milvus nodes. |
But can be deployed by using Amazon EKS. || Potential Bottleneck | As the increase of the number of Elasticsearch cluster. We may need more replicas to balance the query for
avoiding hot zone. | Etcd requires high performance disk for better serving metadata. It could be a bottleneck when the query
increases.
Files on object storage need to be pulled to the local disk and eventually loaded into memory for querying. If
this process switches frequently, the performance may not necessarily be good. || Scaling | Require blue-green deployment to get the online cluster to be scaled | Easy to scale on k8s. The compute node instance number can be changed on demand. |
| Storage | Every data node's hard disk. Require to add new data node to increase the storage. S3 is only used as the
backup storage. | OSS based. S3 can be used for storage all the metrics. |
| AA Switch | Require two identical Elasticsearch cluster. | No need to AA switch. Just reload the query nodes or add more query nodes. |
| Upgrade | Same as the scaling. | Use helm command on k8s cluster. |
Data Writing Flow
Index Flow in Elasticsearch

In this diagram, we can see how a new document is stored by Elasticsearch. As soon as it “arrives”, it is committed to a transaction log called “translog” and to a memory buffer. The translog is how Elasticsearch can recover data that was only in memory in case of a crash.
All the documents in the memory buffer will generate a single in-memory Lucene segment when the “refresh” operation happens. This operation is used to make new documents available for search.
Depending on different triggers, eventually, all of those segments are merged into a single segment and saved to disk and the translog is cleared.
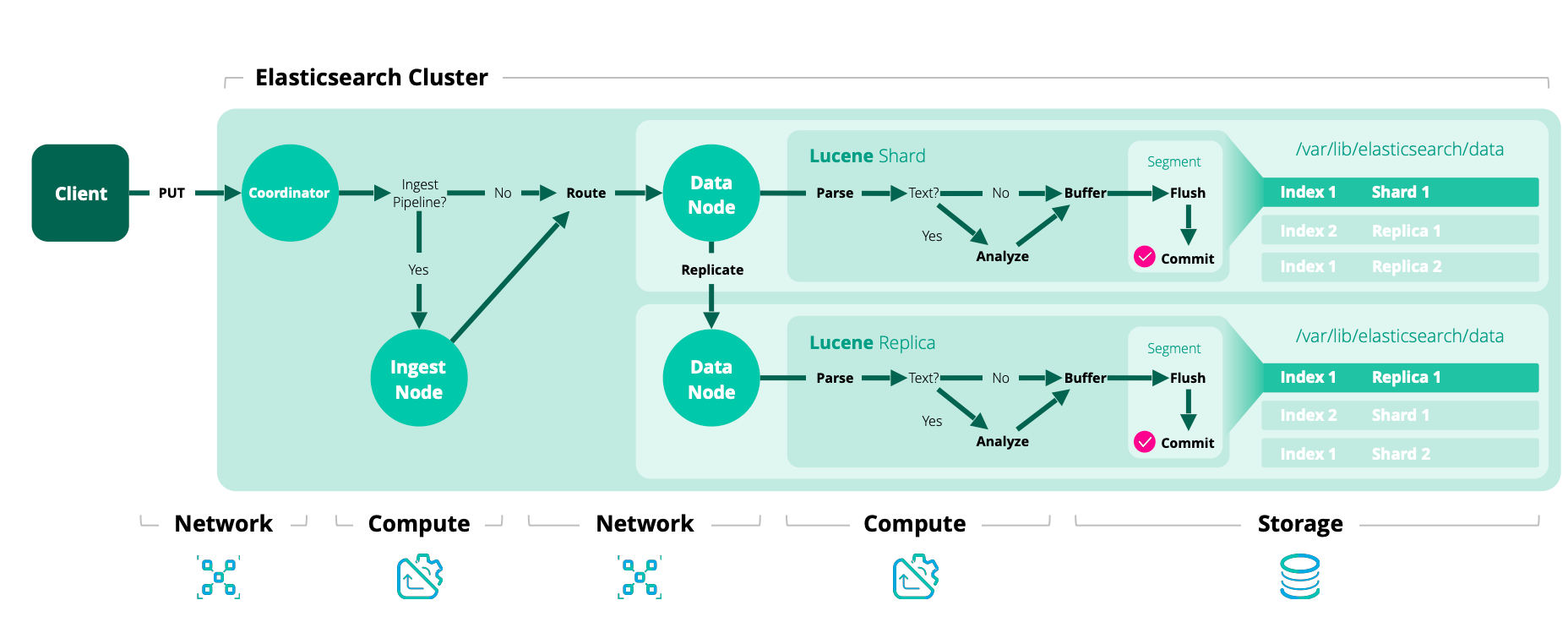
This diagram shows the whole routine for a simple index request.
Data Writing Flow in Milvus
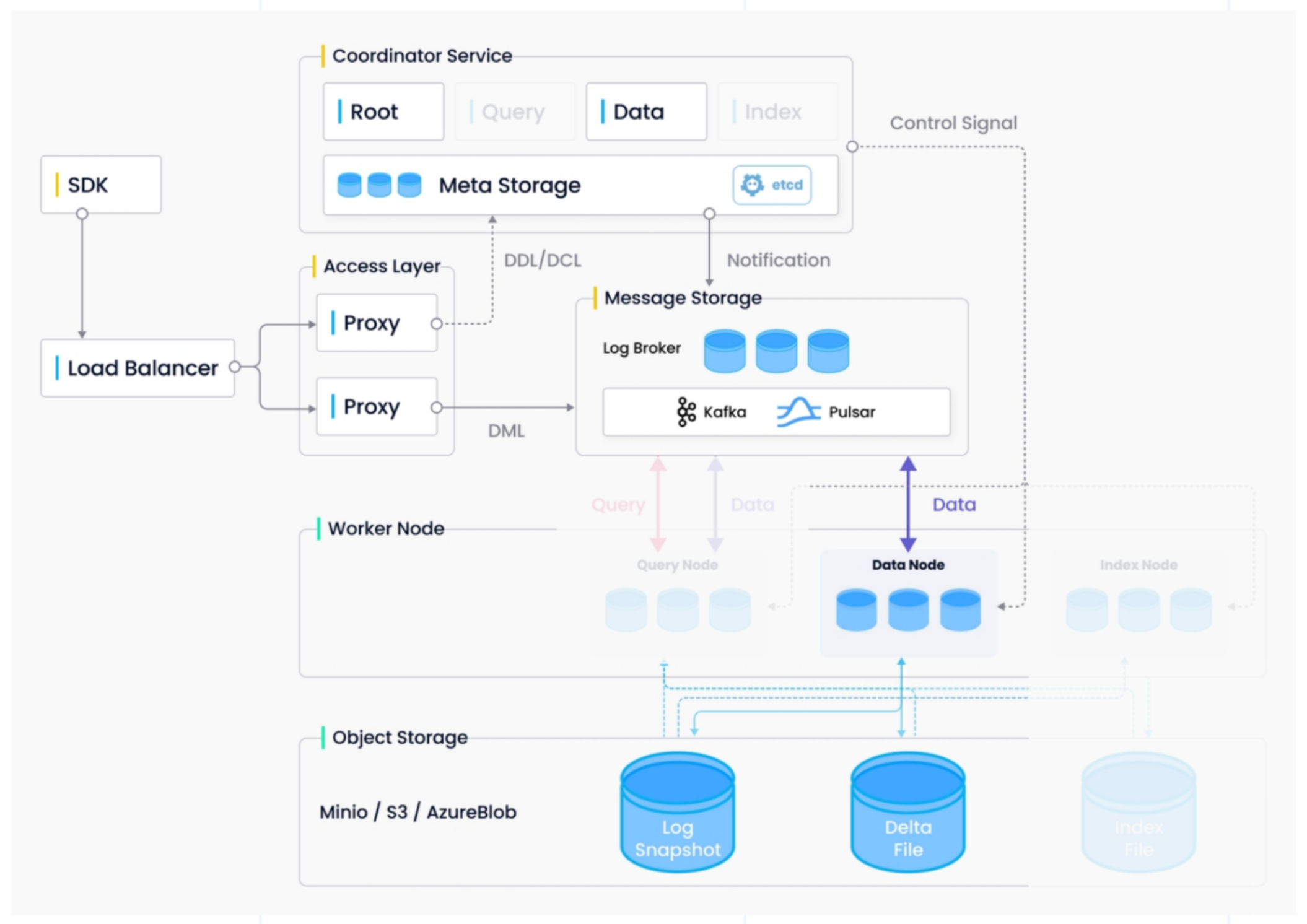
The picture above shows all the modules used in data writing. All the data writing requests are triggered in the SDK. The SDK send the request through the Load Balancer to the proxy node. The number of the proxy node instances could be varied. The Proxy node cached data and request the segment information for writing the data into the message storage.
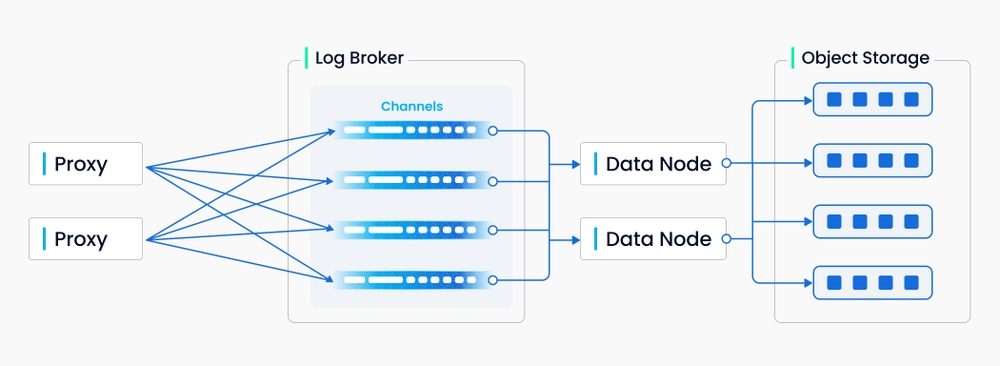
Message storage is mainly a Pulsar based platform for persistence the data. It is the same as the translog in Elasticsearch. The main difference is that Milvus don't need a MQ service in the frontend. You can directly write data through it's interface. And don't need bulk request in Elasticsearch.
The data node consumes the data through message storage and flush it into the object storage finally.
Data model in Vector
Data Model Elasticsearch
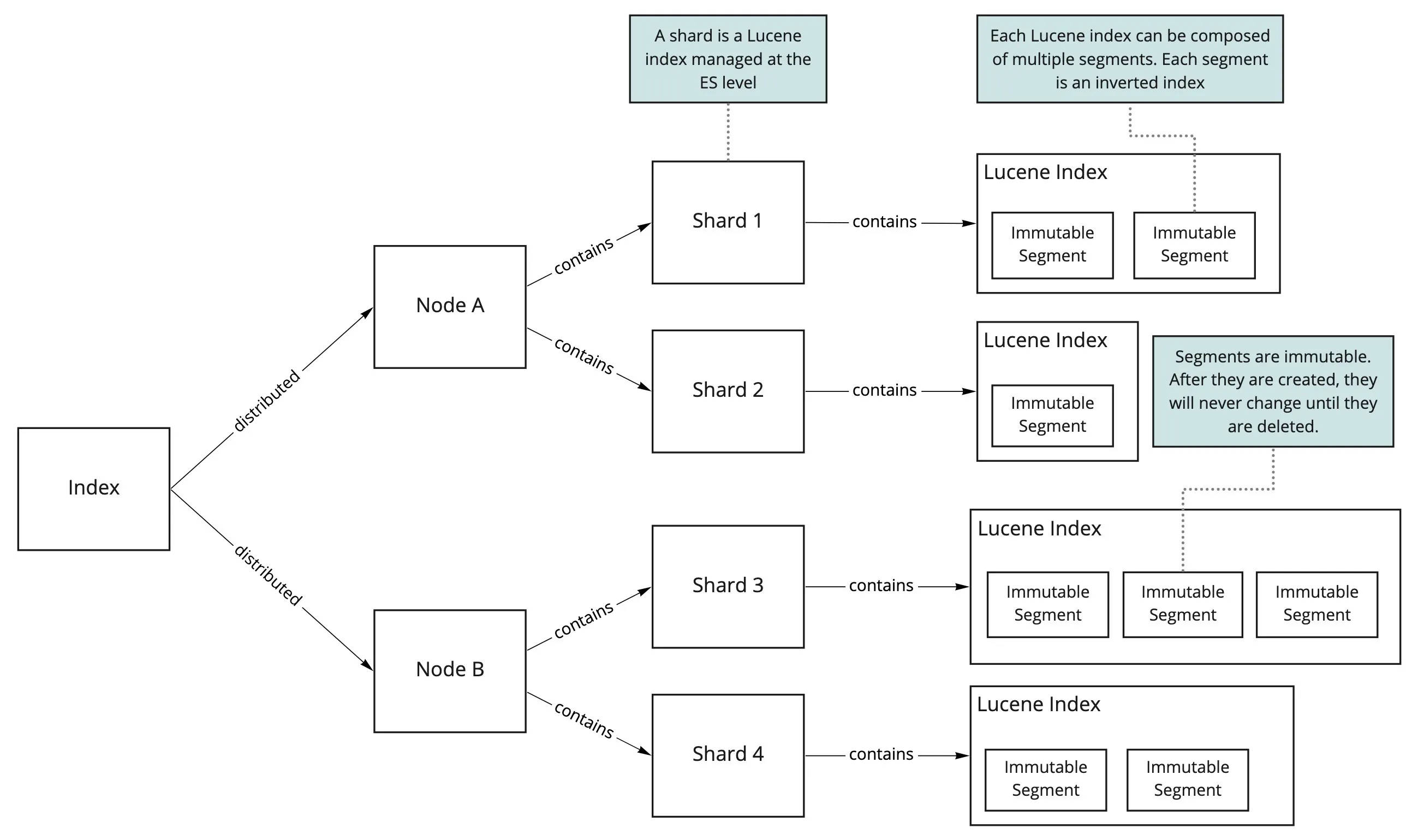
As we can see from the diagram, Elasticsearch shards each Lucene index across the available nodes. A shard can be a primary shard or replica shard. Each shard is a Lucene Index, each one of those indexes can have multiple segments, each segment is an complete HNSW graph.
Data Model in Milvus
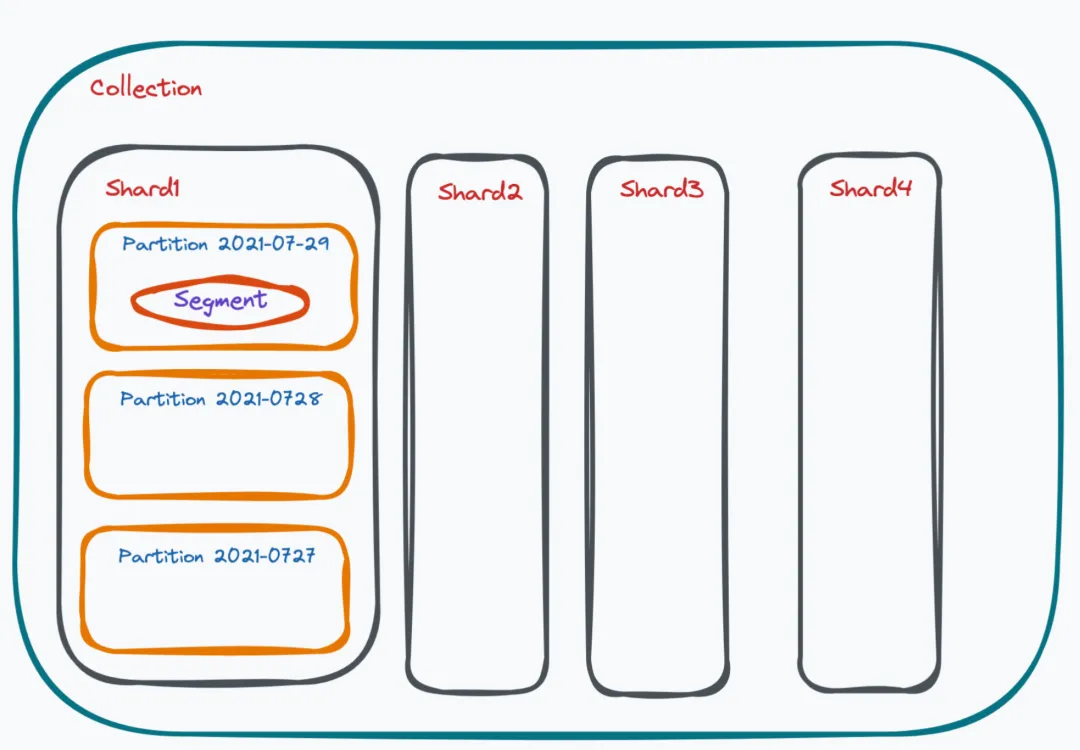
Milvus provides users with the largest concept called Collection, which can be mapped to a table in a traditional database and is equivalent to an Index in Elasticsearch. Each Collection is divided into multiple Shards, with two Shards by default. The number of Shards depends on how much data you need to write and how many nodes you want to distribute the writing across for processing.
Each Shard contains many Partitions, which have their own data attributes. A Shard itself is divided based on the hash of the primary key, while Partitions are often divided based on fields or Partition Tags that you specify. Common ways of partitioning include dividing by the date of data entry, by user gender, or by user age. One major advantage of using Partitions during queries is that if you add a Partition tag, it can help filter out a lot of data.
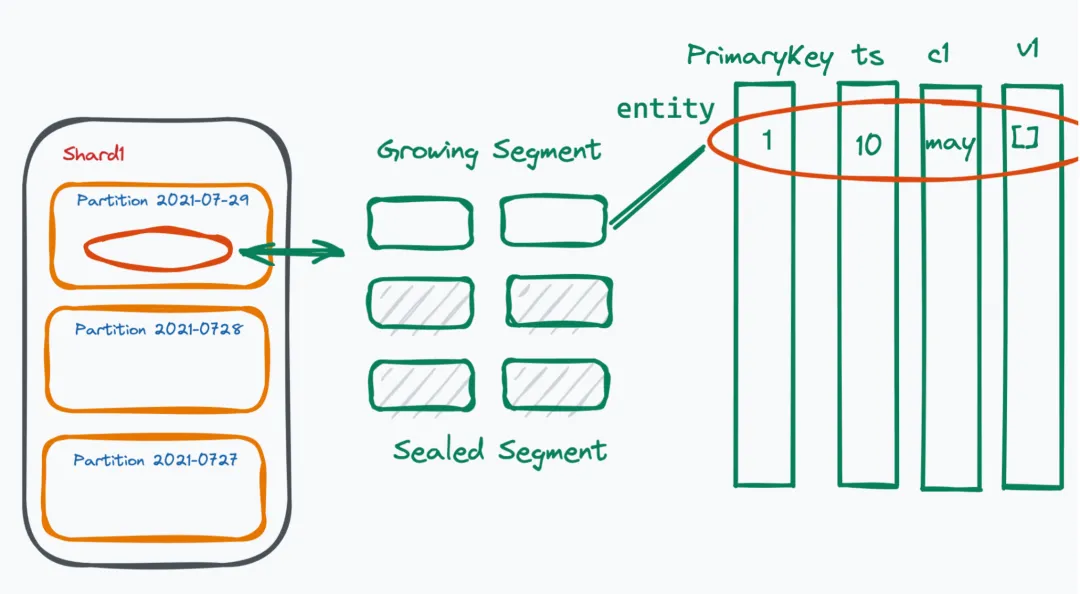
Shard is more about helping you expand write operations, while Partition helps improve read performance during read operations. Each Partition within a Shard corresponds to many small Segments. A Segment is the smallest unit of scheduling in our entire system and is divided into Growing Segments and Sealed Segments. A Growing Segment is subscribed by the Query Node, where users continuously write data until it becomes large enough; once it reaches the default limit of 512MB, writing is prohibited, turning it into a Sealed Segment, upon which some vector indexes are built for the Sealed Segment.
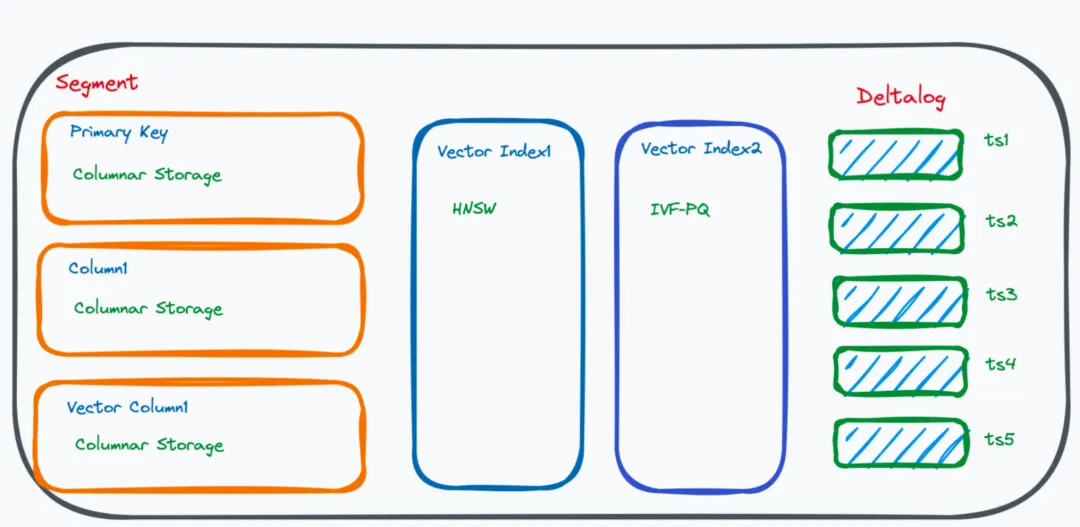
A stored procedure is organized by segments and uses a columnar storage method, where each primary key, column, and vector is stored in a separate file.
Vector Query
Index Types
Both Elasticsearch and Milvus require memory to load vector files and perform queries. But Milvus offers a file-based index type named DiskANN for large datasets, which doesn't require loading all the data but indexes into memory for reducing the memory consumption.
As for Elasticsearch, the dense vector on HNSW is the only solution. The default dimension is float. But Elasticsearch provides the optimized HNSW for reducing the size or increase the performance. To use a quantized index, you can set your index type to int8_hnsw, int4_hnsw, or bbq_hnsw.
| Supported index | Classification | Scenario |
|---|---|---|
| FLAT | N/A | Relatively small dataset |
Requires a 100% recall rate || IVF_FLAT | N/A | High-speed query
Requires a recall rate as high as possible |
| IVF_SQ8 | Quantization-based index | Very high-speed query
Limited memory resources
Accepts minor compromise in recall rate |
| IVF_PQ | Quantization-based index | High-speed query
Limited memory resources
Accepts minor compromise in recall rate |
| HNSW | Graph-based index | Very high-speed query
Requires a recall rate as high as possible
Large memory resources |
| HNSW_SQ | Quantization-based index | Very high-speed query
Limited memory resources
Accepts minor compromise in recall rate |
| HNSW_PQ | Quantization-based index | Medium speed query
Very limited memory resources
Accepts minor compromise in recall rate |
| HNSW_PRQ | Quantization-based index | Medium speed query
Very limited memory resources
Accepts minor compromise in recall rate |
| SCANN | Quantization-based index | Very high-speed query
Requires a recall rate as high as possible
Large memory resources |
Query Flow in Elasticsearch
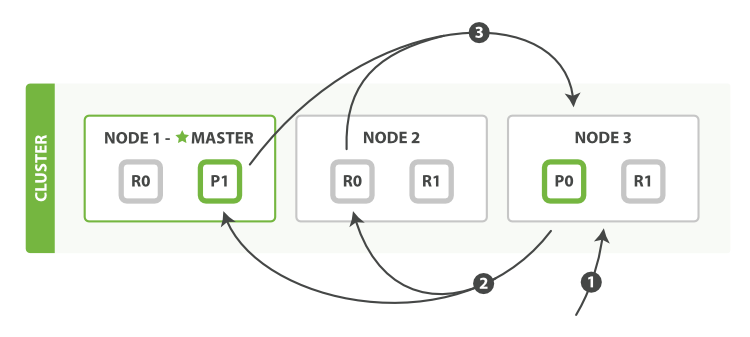
The query phase above consists of the following three steps:
- The client sends a search request to Node 3, which creates an empty priority queue of size from + size.
- Node 3 forwards the search request to a primary or replica copy of every shard in the index. Each shard executes the query locally and adds the results into a local sorted priority queue of size from + size.
- Each shard returns the doc IDs and sort values of all the docs in its priority queue to the coordinating node, Node 3, which merges these values into its own priority queue to produce a globally sorted list of results.
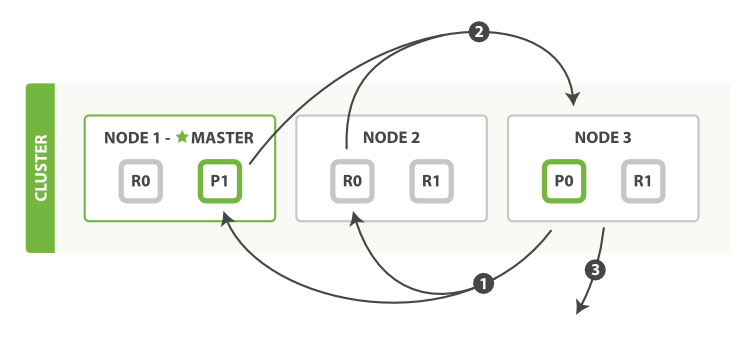
The distributed fetch phase consists of the following steps:
- The coordinating node identifies which documents need to be fetched and issues a multi
GETrequest to the relevant shards. - Each shard loads the documents and enriches them, if required, and then returns the documents to the coordinating node.
- Once all documents have been fetched, the coordinating node returns the results to the client.

Query Flow in Milvus

In the reading path, query requests are broadcast through DqRequestChannel, and query results are aggregated to the proxy via gRPC.
As a producer, the proxy writes query requests into DqRequestChannel. The way Query Node consumes DqRequestChannel is quite special: each Query Node subscribes to this Channel so that every message in the Channel is broadcasted to all Query Nodes.
After receiving a request, the Query Node performs a local query and aggregates at the Segment level before sending the aggregated result back to the corresponding Proxy via gRPC. It should be noted that there is a unique ProxyID in the query request identifying its originator. Based on this, different query results are routed by Query Nodes to their respective Proxies.
Once it determines that it has collected all of the Query Nodes' results, Proxy performs global aggregation to obtain the final query result and returns it to the client. It should be noted that both in queries and results there exists an identical and unique RequestID which marks each individual query; based on this ID, Proxy distinguishes which set of results belong to one specific request.
Compare BM25 between Elasticsearch and Milvus
Why we still care about BM25 in RAG
Hybrid Search has long been an important method for improving the quality of Retrieval-Augmented Generation (RAG) search. Despite the remarkable performance of dense embedding-based search techniques, which have demonstrated significant progress in building deep semantic interactions between queries and documents as the model scale and pre-training datasets have expanded, there are still notable limitations. These include issues such as poor interoperability and suboptimal performance when dealing with long-tail queries and rare terms.
For many RAG applications, pre-trained models often lack domain-specific corpus support, and in some scenarios, their performance is even inferior to BM25-based keyword matching retrieval. Against this backdrop, Hybrid Search combines the semantic understanding capabilities of dense vector search with the precision of keyword matching, offering a more efficient solution to address these challenges. It has become a key technology for enhancing search effectiveness.
How to calculate BM25
BM25 (best matching) is a ranking function used by search engine to estimate the relevance of documents to a given search query.
Here is BM25 calculation formula for a query on document . contains keywords , , … , .
- is the number of the times that the keyword occurs in the document .
- is the length of the document in words.
- (average document length) is the average document length in the text collection from which documents are drawn.
- and are free parameters, used for advanced optimization. In common case, && and .
IDF (inverse document frequency) weight of the query term , where is the total number of documents in the collection, and is the number of documents containing .
Why TF-IDF (BM25) as the main calculation

A term that appears in many documents does not provide as much information about the relevance of a document. Using a logarithmic scale ensures that as the document frequency of a term increases, its influence on the BM25 score grows more slowly. Without a logarithmic function, common terms would disproportionately affect the score.
How Elasticsearch calculate the BM25
By default, Elasticsearch calculates scores on a per-shard basis by leveraging the Lucene built-in function org.apache.lucene.search.similarities.BM25Similarity. It's also the default similarity algorithm in the Lucene's IndexSearcher. If we want to get the index level score calculation, we need to change the search_type from query_then_fetch to dfs_query_then_fetch.
In dfs_query_then_fetch search, we will add the org.elasticsearch.search.dfs.DfsPhase in searching. It will collect all the status in DfsSearchResult which contains the shards document information and hits, etc. The SearchPhaseController will aggregate all the dfs search results into a AggregatedDfs to calculate the score. We can use this search type to get a consistent BM25 score across multiple index.
Do we need use dfs_query_then_fetch in cross-indexes query
The only difference between multiple indexes or shard based BM25 calculation is the IDF. But if the data are well distributed among all the indexes and the document count are large enough in every shard. The difference for IDF could be tiny because we use logarithmic. You can get the growth trend in the second chart above. In this scenario, we don't need to use dfs_query_then_fetch to calculate the global BM25 which requires more resource to cache and calculate.
Sparse-BM25 in Milvus
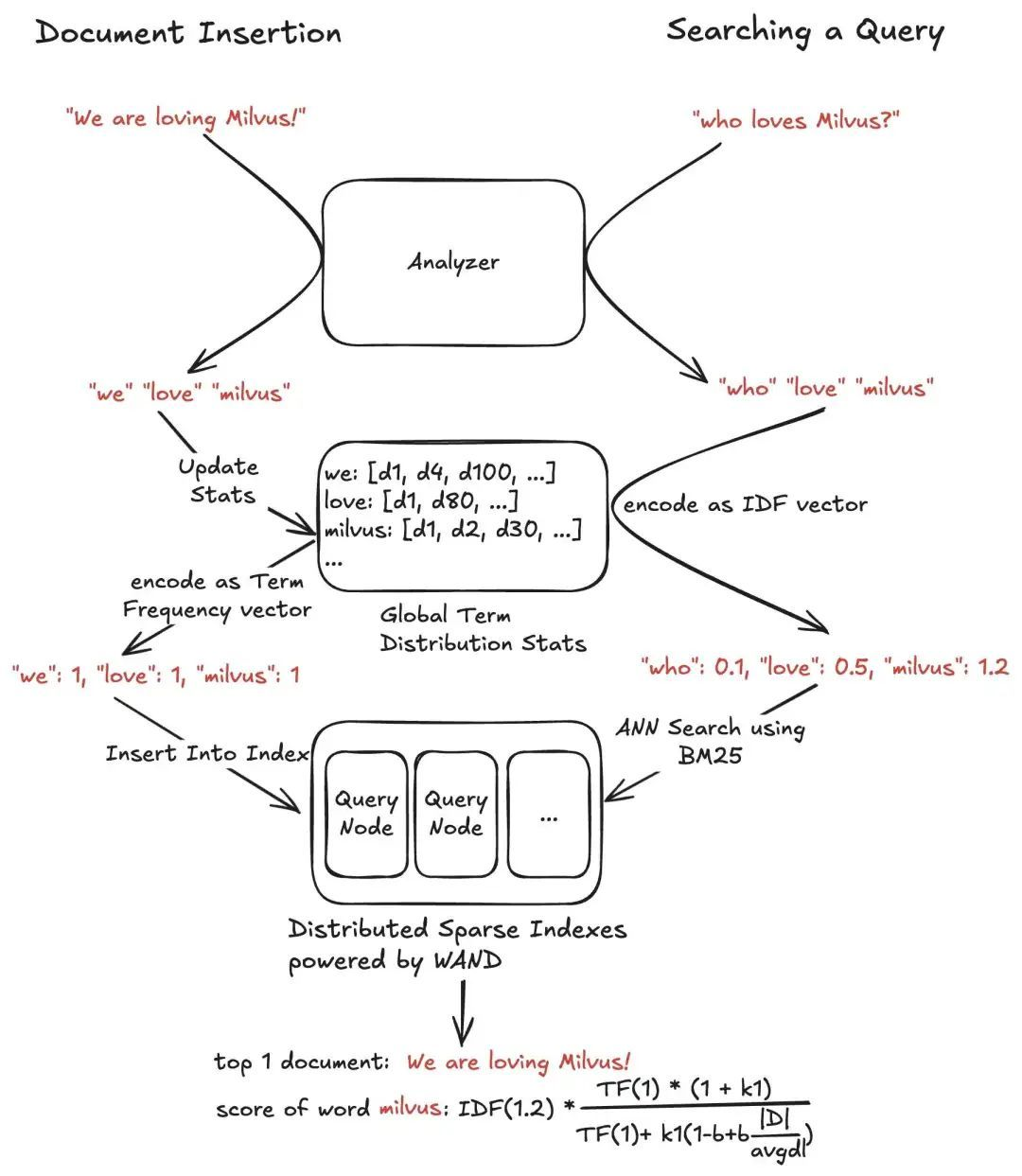
Starting from version 2.4, Milvus supports sparse vectors, and from version 2.5, it provides BM25 retrieval capabilities based on sparse vectors. With the built-in Sparse-BM25, Milvus offers native support for lexical retrieval. The specific features include:
- Tokenization and Data Preprocessing: Implemented based on the open-source search library Tantivy, including features such as stemming, lemmatization, and stop-word filtering.
- Distributed Vocabulary and Term Frequency Management: Efficient support for managing and calculating term frequencies in large-scale corpora.
- Sparse Vector Generation and Similarity Calculation: Sparse vectors are constructed using the term frequency (Corpus TF) of the corpus, and query sparse vectors are built based on the query term frequency (Query TF) and global inverse document frequency (IDF). Similarity is then calculated using a specific BM25 distance function.
- Inverted Index Support: Implements an inverted index based on the WAND algorithm, with support for the Block-Max WAND algorithm and graph indexing currently under development.
Pros and Cons of Sparse-BM25 in Milvus
- Full-text search in Milvus is still under heavy development which can see a lot of bugs in GitHub.
- Full-text search require creating extra Spare-Index on collections (the document set) which isn't out of box like Elasticsearch.
- Hybrid search on a collection with both ANN with BM25 can be ranked in a single requests and get the top K like Elasticsearch's reciprocal rank fusion (RRF) since 8.8.0.
{kind=link}
{kind=link}
博主写的好,外加这个主题模板也漂亮,怎么看怎么舒服!
文章虽长,但版面漂亮呀。
专业!!!
没想到你还是技术流。。。。